Testing in AgentMark
AgentMark provides a comprehensive testing workflow to validate, measure, and improve your prompts:- Datasets — Test prompts against collections of input/output pairs to catch regressions and validate behavior
- Evaluations — Score prompt outputs automatically using custom evaluation functions
- Experiments — Run prompts against datasets with evals, compare versions, and track performance
- Annotations — Manually label and score traces for human-in-the-loop evaluation
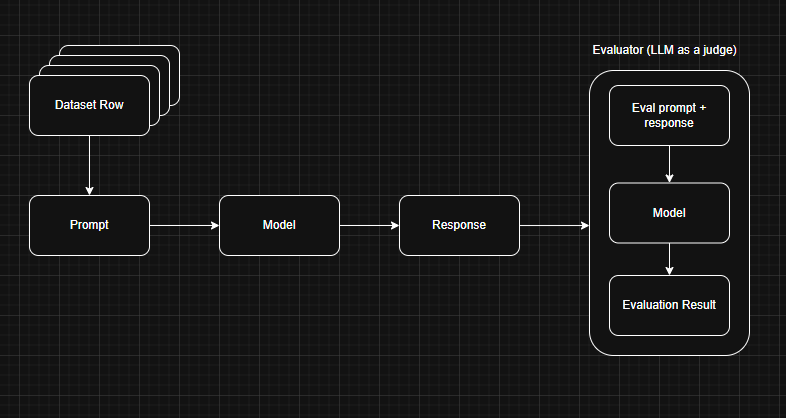
How It Works
- Create a dataset with test inputs and expected outputs (JSONL format)
- Write evaluation functions that score outputs (pass/fail, numeric scores, labels)
- Connect them to prompts via
test_settingsin the prompt frontmatter - Run experiments from the platform or CLI to test all dataset items
- Review results — scores, pass rates, and individual outputs in the dashboard
- Annotate traces with human judgment for additional insight
Datasets
Datasets are collections of input/output pairs in JSONL format that define your test cases. Each item specifies the input props for a prompt and an optional expected output for comparison.- Create and manage datasets through the platform UI or as local JSONL files
- Run datasets against prompts to generate bulk results
- View detailed traces for each run item
Evaluations
Evaluations are functions that automatically score prompt outputs. Register eval functions in your client config, reference them in prompt frontmatter, and they run automatically during experiments.- Score outputs with numeric values, pass/fail status, labels, and reasons
- Use reference-based, heuristic, or LLM-as-judge approaches
- View eval results alongside traces in the dashboard
Experiments
Experiments run a prompt against a dataset with evaluations. Use them to validate prompt changes, compare model configurations, and enforce quality thresholds before deploying.- Run from the platform UI or via
agentmark run-experimentin the CLI - Output results as tables, CSV, JSON, or JSONL
- Set pass-rate thresholds to gate deployments
Annotations
Annotations let team members manually score and label individual traces in the dashboard. Use them for human-in-the-loop evaluation, edge case documentation, and creating training datasets from production data.- Add scores, labels, and detailed reasoning to any span
- Complement automated evals with human judgment
- Review annotations alongside automated scores in the Evaluation tab
Have Questions?
We’re here to help! Choose the best way to reach us:
- Join our Discord community for quick answers and discussions
- Email us at hello@agentmark.co for support
- Schedule an Enterprise Demo to learn about our business solutions